キーワード stable-diffusion が含まれる動画 : 166 件中 1 - 32 件目
種類:
- タグ
- キーワード
対象:


AI画像生成「Stable Diffusion」 の動画版【Deforum Stable Diffusion】でテキストからムービーを生成してみた。モチーフは”18世紀の肖像画”。

AI作画ができるPythonプログラムStable Diffusionの動画版 Deforum Stable Diffusion を使ってみた。
「18世紀の肖像画、花、ロセッティ風、ブーグロー風、ミュシャ風の絵柄」などの単語や短い文章を英語でプログラムに与えてやると、文字から画像を生成できる。時間に沿って背景の雲の量を増やす、とか花の色や量を変える、人物の目を閉じさせる、などの指定を文字で指定すると、そのような変化を加えてくれたりもする。
以下のリンクで GoogleColabを使ってブラウザ上からDeforum Stable Diffusionを使えます。 https://colab.research.google.com/github/deforum/stable-diffusion/blob/main/Deforum_Stable_Diffusion.ipynb
同じDeforum Stable Diffusionを、Githabからプログラムを自分のPCにダウンロードして使う場合は、このページからできる。
https://github.com/HelixNGC7293/DeforumStableDiffusionLoc











stable diffusionで邪神ちゃん達と遊ぼう

邪神ちゃんをstable diffusionで遊んでみた。
遊びながら動画を作ってみた・・なので中身は微妙。
思いどうりにはならないね。
使用素材
邪神ちゃんドロップキック_立ち絵「ペルセポネ2世」
邪神ちゃんドロップキック_立ち絵「邪神ちゃん」
フリーBGM「ardor」/作(編)曲 : マニーラ

F - ヒズミ零 feat.flower

Bagatelle No.06 ♩=200
あけましておめでとうございます。ヒズミ零です。
新年早々こんな曲で すみません…
Fxxk Fxxk Fxxk Fxxk Fxxk
Fxxk Fxxk Fxxk Fxxk Fxxk Fxxk Fxxk
Fxxk Fxxk Fxxk Fxxk Fxxk
Fxxk Fxxk Fxxk Fxxk Fxxk Fxxk Fxxk
Fxxk Fxxk Fxxk Fxxk Fxxk Fxxk Fxxk
(A Brexit Tankaです)
■イラスト / Stable Diffusion (AI)
https://huggingface.co/spaces/stabilityai/stable-diffusion
■映像 / アオねこ
https://twitter.com/Hizumi_Rei
■歌詞 / アオねこ
https://twitter.com/Hizumi_Rei
■音楽 / ヒズミ零
https://twitter.com/Hizumi_Rei
■歌 / flower [VOCALOID]
□歌詞・オフボーカルのダウンロードはこちら□
まっててね
□楽曲解説はこちら□
まっててね
□イラスト裏話はこちら□
まっててね

超高速CPU画像生成AI FastSDCPUをSteam Deck+Ubuntu23.04+OpenVINOで使ってみた
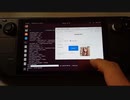
FastSD CPUはStable diffusionの画像生成AIを低Stepでオフライン作成出来るソフトです。CPUだけでも本家Stable diffusionが4分→13秒まで高速化出来る様になります。
デフォルト512x512 1Stepを12.83 秒/枚で生成出来ました。多分CPUのみでGPUは使っていないはずです。


Stable Diffusionでのアニメーション動画制作解説:AIひろゆき解説

Deforum_Stable_Diffusion.ipynb - Colaboratory - Google Colab
https://colab.research.google.com/github/deforum/stable-diffusion/blob/main/Deforum_Stable_Diffusion.ipynb
ぼくのTesla T4取らないでね(´・ω・`)
するめをなんだと思ってんだ

ストーリー ChatGPTにより生成
背景 stable-diffusion により生成
VOICEVOX:四国めたん
VOICEVOX:ずんだもん
VOICEVOX:春日部つむぎ
銀河鉄道の Ave Maria(アヴェ・マリア) / 猫村いろは Synthesizer V 2 体験版

画像はイメージです
SV2猫村さん体験版来たので https://x.com/ahsoft/status/1978341552033268127
あと Stable Diffusion 使ってイメージ画像付けてみました。
作詞・作曲・編曲 kadotanimitsuru
歌: Synthesizer V 2 AI 猫村いろは 体験版
コーラス: VOCALOID6 Voicebank Po-uta
夢 映す 罪人
捕われた籠の中
貴方と歩む夢を
見果てぬ 銀河
Ave Maria
(Sancta Maria)
gratia plena
(Dominus tecum)
打ち鳴らす鼓動
まろび出た旋律
何を願い
求めたのかも
行く先も無くて
消えて行く
夢 求む 咎人
走り続く線路で
消えた輝き探し
喘いで 餓えて
彷徨い 歩むの
Ave Maria
(Sancta Maria)
gratia plena
(Dominus tecum)
nc156924 教会エーデル
Stable DiffusionStability AI https://stability.ai/
Stable Diffusion WebUI Forge https://github.com/lllyasviel/stable-diffusion-webui-forge
WAI-illustrious-SDXL - v15.0 https://civitai.com/models/827184/wai-nsfw-illustrious-sdxl
銀河鉄道の Ave Maria(アヴェ・マリア) / 猫村いろは Synthesizer V 2

sm45536143 を Grok Imagine で動画化してみました。
作詞・作曲・編曲 kadotanimitsuru
歌: Synthesizer V 2 AI 猫村いろは
コーラス: VOCALOID6 Voicebank Po-uta
夢 映す 罪人
捕われた籠の中
貴方と歩む夢を
見果てぬ 銀河
Ave Maria
(Sancta Maria)
gratia plena
(Dominus tecum)
打ち鳴らす鼓動
まろび出た旋律
何を願い
求めたのかも
行く先も無くて
消えて行く
夢 求む 咎人
走り続く線路で
消えた輝き探し
喘いで 餓えて
彷徨い 歩むの
Ave Maria
(Sancta Maria)
gratia plena
(Dominus tecum)
nc156924 教会エーデル nc156924
Stable DiffusionStability AI https://stability.ai/
Stable Diffusion WebUI Forge https://github.com/lllyasviel/stable-diffusion-webui-forge
WAI-illustrious-SDXL - v15.0 https://civitai.com/models/827184/wai-nsfw-illustrious-sdxl
Grok Imagine https://grok.com/imagine
タカハシの下の名前を一向に覚えようとしないささらちゃんのお話し【CeVIOトーク】

下の名前が公表されてルンルン気分のタカハシ君と、頑なに己の公式設定を守り通すささらちゃんの物語です。
声の出演
知声(VoiSona) タカハシ(CeVIO) さとうささら(CeVIO) すずきつづみ(CeVIO)
第3回CeVIOクリエイト祭
https://www.nicovideo.jp/watch/sm42987926
CeVIO
https://cevio.jp/
VoiSona
https://voisona.com
背景画像(台所)
Stable Diffusion 2.1 Demo
https://huggingface.co/spaces/stabilityai/stable-diffusion
格安SteamdeckにUbuntu25.04とvulkanとStable-Diffusion.cppを入れて内臓GPU 4GBで高速画像生成AI。GTX1650相当だが割りと高速で快適

ゲーム機にしておくには惜しい性能なSteamdeck。vulkanで内臓GPU使えます。モデルはStable diffuson 2.1 turbo。動画では20枚の画像生成を1分3秒で作成しました。
【AI MMD】 シリアス 極楽浄土

MMDのMP4をstable-diffusion-webuiのプラグインのmov2movに直接読み込ませAI化しました。
まだカメラモーションを入れるとAIが追従出来ないのでAI MMDでのローアングルはしばらくお預けです。
mov2movが速い動きに対応できるようになると良いのですが
ターミナルでブラウザを使わずにFastSDCPUで画像生成AI。省メモリかつzshを使えばrepeat処理でエンドレスAI出来ます。Androidでも動きました
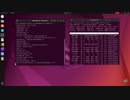
WebUIを使わずにTerminalでStable-Diffusionの生成AIを動かしました。ブラウザが無い分少ないメモリで動いて、zshのrepeatコマンドと併用すれば繰り返し処理が出来ます。他のコマンドとの組み合わせも出来るので色々な処理が可能です。export OPENBLAS_NUM_THREADS=1コマンドを先に入れておけばAndroidでも動作します。
AndroidタブレットにTermuxとUbuntuを入れローカルCPU超高速FastSDCPUで爆速生成AI。標準25分/枚がLCMでわずか90秒/枚。メモリ14GB推奨。お金をかけず爆速化最高

AndroidにTermuxとUbuntuをproot distro install ubuntuで入れて、超高層LCMのStable-DiffusionのFastSD CPUを動作しています。AndroidのCPUはx86より遅いので時間がかかりますがLCMを使うとステップ回数が削減しても生成AI画像が作れるので高速化しています。メモリを最低14GB使用しますのでSwap推奨
【stable diffusion】 をどんな感じに使うかを解説する動画

https://github.com/AUTOMATIC1111/stable-diffusion-webui
使ったリポジトリ
ryzen5800h rtx3060mobile
当時12.8万円のpcでローカル生成
動画は三倍速です
りんちゃのアカウント @rin_sns_
今すぐできるAIくんでの画像作り+デカモチモチ+素材集

おすすめGUIとかを概要にかきまんた
広告ほんとにありがとナス!
とりあえず
very high details by william turner art, greg rutkowski and alphonse mucha
入れたらほんとに大抵いい感じになります
前までの動画に使った画像もまとめました、でも一部日本語にリネームしたときinfoどっかいっちゃった…なんか悲しいね 生きてるって
StableDiffusionGui-v1.2.0
https://nmkd.itch.io/t2i-gui
Stable Diffusion GRisk GUI
https://grisk.itch.io/stable-diffusion-gui
おすすめprompt参考
https://lexica.art/
(ほんとに超絶おすすめ)
AI で画像生成するテキストを作成ジェネレーター
https://ai-copywriter.jp/free/136
作った画像集
https://xfs.jp/kjYYdn
Artroomが最強かもしれない
https://gigazine.net/news/20220902-artroom-stable-diffusion/
あーっ!!! うーーーっす!!! おうううっす!!!
stable-diffusion-webuiってチョーS(Sugoi GUI)だよな!!!!!
https://gigazine.net/news/20220907-automatic1111-stable-diffusion-webui/