キーワード stable-diffusion が含まれる動画 : 166 件中 129 - 160 件目
種類:
- タグ
- キーワード
対象:




【Stablediffusion】で神絵を連発する方法【徹底解説】ずんだもんでもわかるAI画像生成【voicevox】
画像生成AI「Stable Diffusion」を使って画像を作る方法を徹底解説。この動画を最後まで視聴し、下記のリンク先を見ながら画像を生成していくと、神絵を連発できるようになります。無料で使えるので、ぜひお試しください。
Stable Diffusion Demo
https://huggingface.co/spaces/stabilityai/stable-diffusion
DeepL
https://www.deepl.com/ja/translator
Lexica
https://lexica.art/
#voicevox #ずんだもん #stablediffusion
Twitter https://twitter.com/hat0pige0n
YouTube https://www.youtube.com/watch?v=iXeUS13_IJg
○立ち絵
九州そら https://seiga.nicovideo.jp/seiga/im10...
ずんだもん https://seiga.nicovideo.jp/seiga/im10...
春日部つむぎ https://seiga.nicovideo.jp/seiga/im10...
○音声
VOICEVOX:九州そら
VOICEVOX:ずんだもん
VOICEVOX:春日部つむぎ
https://voicevox.hiroshiba.jp/
○BGMと効果音
レトロパーティー 甘茶の音楽工房
https://amachamusic.chagasi.com/music_retroparty.html
効果音ラボ https://soundeffect-lab.info/
○背景と画像素材
PhotoAC https://www.photo-ac.com/
ニコニ・コモンズ https://commons.nicovideo.jp/
○ゆっくりムービーメーカー4を使って編集しました
https://manjubox.net/ymm4/
銀河鉄道の Ave Maria(アヴェ・マリア) / 猫村いろは Synthesizer V 2

sm45536143 を Grok Imagine で動画化してみました。
作詞・作曲・編曲 kadotanimitsuru
歌: Synthesizer V 2 AI 猫村いろは
コーラス: VOCALOID6 Voicebank Po-uta
夢 映す 罪人
捕われた籠の中
貴方と歩む夢を
見果てぬ 銀河
Ave Maria
(Sancta Maria)
gratia plena
(Dominus tecum)
打ち鳴らす鼓動
まろび出た旋律
何を願い
求めたのかも
行く先も無くて
消えて行く
夢 求む 咎人
走り続く線路で
消えた輝き探し
喘いで 餓えて
彷徨い 歩むの
Ave Maria
(Sancta Maria)
gratia plena
(Dominus tecum)
nc156924 教会エーデル nc156924
Stable DiffusionStability AI https://stability.ai/
Stable Diffusion WebUI Forge https://github.com/lllyasviel/stable-diffusion-webui-forge
WAI-illustrious-SDXL - v15.0 https://civitai.com/models/827184/wai-nsfw-illustrious-sdxl
Grok Imagine https://grok.com/imagine
格安SteamdeckにUbuntu25.04とvulkanとStable-Diffusion.cppを入れて内臓GPU 4GBで高速画像生成AI。GTX1650相当だが割りと高速で快適

ゲーム機にしておくには惜しい性能なSteamdeck。vulkanで内臓GPU使えます。モデルはStable diffuson 2.1 turbo。動画では20枚の画像生成を1分3秒で作成しました。
AIに浅深メンバー描かせてみた【バイザウェイ編】

半年前くらいに撮影したもの
Twitter
浅瀬の深海魚達公式アカウント➡https://twitter.com/asashin_kousiki
参加者一覧↓
・リューエン
・うしろん
・バイザウェイ
・ポンチョ次郎
・ナツ
・ゴリラ
使用ツール:https://github.com/AUTOMATIC1111/stable-diffusion-webui
AIに浅深メンバー描かせてみた【ゴリラ編】

話題の生成系AIを使ってみたかった
Twitter
浅瀬の深海魚達公式アカウント➡https://twitter.com/asashin_kousiki
参加者一覧↓
・リューエン
・うしろん
・バイザウェイ
・ポンチョ次郎
・ナツ
・ゴリラ
使用ツール:https://github.com/AUTOMATIC1111/stable-diffusion-webui






【AI / Stable Diffusion】イラストを描き直させ続けAIを調教しようとするスパルタな俺【Inpainter】

今回はAIに描かせたサッカーするババア動画ではなく、
淡々とAI生成の風景画スライドショー動画でございます。
大元は、前回概要と同じく「文字列から画像を描画してくれるAI」。
→https://huggingface.co/spaces/stabilityai/stable-diffusion
この数週間、Stable Diffusion系のAIサービスを試してたんです。
んで、今回は、気に入らない箇所を描き換えできる機能を追加した、
Inpainterなるもので、欲しい要素を単語で羅列(カンマで区切って)し、
コイツは資料になるようなイラストを描いてくれるのか?と、
何枚も何枚も描かせてコキ使ってやりましたよ、ええ、あ〜い。
Inpainter→https://inpainter.vercel.app/paint
こういった画像AIは、肖像権や著作権に明確に触れるを避ける為なのか、
リアルな写真でもイラストでも"顔"がヘドロのように崩れてしまうわけ。
極稀に、誰か判る程度のクオリティで描きやがるので、
マトモ顔面ガシャとして遊ぶという趣もあるにはあります。
私の場合は、メガネ男子を描かせた時、造詣深いプロレス実況でお馴染み、
ニッポン放送の清野アナらしき顔が描かれましたよ。
新日本プロレスの一夜明け会見動画でよく見るあの横顔がね。
このAIはまだ発展途上というか、絵を描く楽しさを知ったばかりの子供さ。
その頃の自分を思い出してみて下さいよオッカナイ顔した絵師のみなさん、
好きなアニメや漫画を模写し模倣しまくったからこそ今があり、そのお陰で、
ご自慢の"自分のタッチ"とやらで、承認欲求やら商売で食えてるんでしょ?
そもそも、本当にオリジナリティのある一流の作家は、
自分がオリジンでない事を何度も思い知って一流になった人達だろうし。
お釈迦様の掌で飛び回る猿を何周もやっきた人達だと思うわけ、一部を除き。
だからね、今回はAIが描いた絵を、これまたアップロードし、
前回のAI絵を、文字列を追加しつつ更にAIに描き直しさせ続けたわけだ。
自分がそうして学習してきたようにね、最後の方は少し可能性感じるでしょ?
色んな人のタッチを徐々に追加し混ぜ、描かせる物や色も変えながらね。
そうやって磨き気付いていくものじゃないの、独自性や個性ってさ。
他人の著作物食うバケモノなら自分のクソたらふく喰わせて薄め相殺すりゃいい。
それでも何かしら気付きがあるのが創作の面白さなんだと思うよ、俺はね。
【stable diffusion】 をどんな感じに使うかを解説する動画

https://github.com/AUTOMATIC1111/stable-diffusion-webui
使ったリポジトリ
ryzen5800h rtx3060mobile
当時12.8万円のpcでローカル生成
動画は三倍速です
りんちゃのアカウント @rin_sns_
stable diffusionで邪神ちゃん達と遊ぼう2

邪神ちゃんをstable diffusionで遊んでみた。
遊びながら動画を時間ぎりぎりまで作ってみた。
使用素材
邪神ちゃんドロップキック_立ち絵「邪神ちゃん」
nc281625~nc281638
フリーBGM「ardor」/作(編)曲 : マニーラ
stable diffusionで邪神ちゃん達と遊ぼう

邪神ちゃんをstable diffusionで遊んでみた。
遊びながら動画を作ってみた・・なので中身は微妙。
思いどうりにはならないね。
使用素材
邪神ちゃんドロップキック_立ち絵「ペルセポネ2世」
邪神ちゃんドロップキック_立ち絵「邪神ちゃん」
フリーBGM「ardor」/作(編)曲 : マニーラ
【無料】Stable Diffusionのinpaintingを使ってColabで遊ぼう!

(2023年1月8日追記)この動画の情報は古くなったのでお勧めしません。以下の動画でColabをメンテナンスしているので、良かったら見ていただけたら嬉しいです。
WD1.4を使ったワークフローをAUTOMATIC1111版WebUIで学ぶ
sm41602488
※ブラウザはGoogle Chromeが一番相性がいいです。
※画像のアップロードで動かない場合があり、クッキーの使用が禁止されてる可能性があります。
【動画目次】
#00:34 HuggingFaceのアクセストークンを発行
■Stable Diffusionのinpaintingが動作するcolabのノートブック
https://colab.research.google.com/gist/thx-pw/dc08b4367f4136e1d93361a1ea84d51b/in-painting-with-stable-diffusion-using-diffusers-with-canvas-drawing.ipynb
■HuggingFaceのアクセスリポジトリする場所
https://huggingface.co/CompVis/stable-diffusion-v1-4
■前回の動画
sm40977760
■YouTubeもよろしく!
https://www.youtube.com/channel/UCdSArCQC3yg_lkhGxixfh3g
【使用した絵】
■AvatarSample_G(Victoria Rubin)
https://vroid.pixiv.help/hc/ja/articles/360014900233-AvatarSample-G
【使用した音】
■VOICEVOX
https://voicevox.hiroshiba.jp/
冥鳴ひまり
■ニコニ・コモンズ
https://commons.nicovideo.jp/
shuffle shuffle
韓非子は女の子?【AI画像生成】【Stable Diffusion】国語の教科書のお話をAIに描かせてみた結果【ずんだもんでもわかる国語】【voicevox】
画像生成AI「Stable Diffusion」を使って、国語の教科書に載っている作品のイメージ画像を生成しました。
説明文によって全くわからない内容になったりして面白かったので、ずんだもんたちが答えるクイズ形式にしました。一緒に答えてみてください。
↓こちらのStable Diffusion Demoというサイトを使って生成しました。
https://huggingface.co/spaces/stabilityai/stable-diffusion
Deelp https://www.deepl.com/ja/translator
Twitter https://twitter.com/hat0pige0n
YouTube https://youtu.be/cTu-YMqVRU4
○立ち絵
九州そら https://seiga.nicovideo.jp/seiga/im10...
ずんだもん https://seiga.nicovideo.jp/seiga/im10...
春日部つむぎ https://seiga.nicovideo.jp/seiga/im10...
○音声
VOICEVOX:九州そら
VOICEVOX:ずんだもん
VOICEVOX:春日部つむぎ
https://voicevox.hiroshiba.jp/
○BGMと効果音
レトロゲームセンター https://amachamusic.chagasi.com/music_retrogamecenter.html
甘茶の音楽工房 https://amachamusic.chagasi.com/ https://commons.nicovideo.jp/material/nc243942
【BGM】 疑惑の霧 (シンセなホラー) https://commons.nicovideo.jp/material/nc134331
○背景と画像素材
PhotoAC https://www.photo-ac.com/
ニコニ・コモンズ https://commons.nicovideo.jp/
○ゆっくりムービーメーカー4を使って編集しました
https://manjubox.net/ymm4/
Stable Diffusionでドラえもん【バイバイン】

Stable Diffusionでドラえもんを作成しました。
バイバインは名作ですね。
画像
Stable Diffusion
https://huggingface.co/spaces/stabilityai/stable-diffusion
声
voicevox
https://voicevox.hiroshiba.jp/
編集ソフト
DaVinci Resolve
https://www.blackmagicdesign.com/jp/products/davinciresolve


ターミナルでブラウザを使わずにFastSDCPUで画像生成AI。省メモリかつzshを使えばrepeat処理でエンドレスAI出来ます。Androidでも動きました
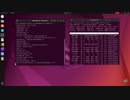
WebUIを使わずにTerminalでStable-Diffusionの生成AIを動かしました。ブラウザが無い分少ないメモリで動いて、zshのrepeatコマンドと併用すれば繰り返し処理が出来ます。他のコマンドとの組み合わせも出来るので色々な処理が可能です。export OPENBLAS_NUM_THREADS=1コマンドを先に入れておけばAndroidでも動作します。
AndroidタブレットにTermuxとUbuntuを入れローカルCPU超高速FastSDCPUで爆速生成AI。標準25分/枚がLCMでわずか90秒/枚。メモリ14GB推奨。お金をかけず爆速化最高

AndroidにTermuxとUbuntuをproot distro install ubuntuで入れて、超高層LCMのStable-DiffusionのFastSD CPUを動作しています。AndroidのCPUはx86より遅いので時間がかかりますがLCMを使うとステップ回数が削減しても生成AI画像が作れるので高速化しています。メモリを最低14GB使用しますのでSwap推奨
超高速CPU画像生成AI FastSDCPUをSteam Deck+Ubuntu23.04+OpenVINOで使ってみた
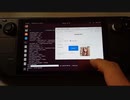
FastSD CPUはStable diffusionの画像生成AIを低Stepでオフライン作成出来るソフトです。CPUだけでも本家Stable diffusionが4分→13秒まで高速化出来る様になります。
デフォルト512x512 1Stepを12.83 秒/枚で生成出来ました。多分CPUのみでGPUは使っていないはずです。
StableDiffusionでエラーが出たら、ノートブックの更新を確認してみよう!

初心者向けですが、StableDiffusionでエラーが出たら、ググっていろいろコードを変えたりしてうまくいくこともありますが、今までのエラーでノートブックの更新がされていなくて、手動ですると簡単に直ったということがあるので、ぜひご参考にしてみてください。
TheLastBenさんのリポジトリ:https://github.com/TheLastBen/fast-stable-diffusion


automatic1111でLoraモデルを使う方法解説【Stable Diffusion】
fast-stable-diffusion https://github.com/TheLastBen/fast-stable-diffusion
Lora拡張 https://github.com/kohya-ss/sd-webui-additional-networks
Lora model https://civitai.com/
有料記事を書きました https://note.com/shinao39/n/ndac490e7855f
Loraモデルをautomatic1111で使う方法を説明します。Loraは複数モデルを同時に適用させる事が可能です。Loraを使うには付属の機能を使うか、拡張機能を使います。
チャンネル登録よろしくです https://bit.ly/shinano-sub
ウィッシュリスト https://www.amazon.jp/hz/wishlist/ls/3D0A081RG7SGQ?ref_=wl_share
Blog https://shinanomatsumoto.hatenablog.com/
note https://note.com/shinao39/
#automatic1111
#StableDiffusion
#Lora
#generativeai
#shinanomatsumoto
【画像生成】AIでレシピから料理の画像は作れるのか?
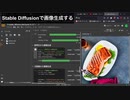
画像生成AIを使って料理の画像を生成する実験をしました。ChatGPTも登場します。
ラムダ技術部さんというYouTuberの動画を参考にしました。
ラムダ技術部さんのチャンネル: user/48313347
参考にした動画: watch/sm41035680
Stable Diffusion: https://ja.wikipedia.org/wiki/Stable_Diffusion
https://huggingface.co/spaces/stabilityai/stable-diffusion
ChatGPT: https://openai.com/blog/chatgpt/
<使用した素材>
BGM: DOVA-SYNDROME https://dova-s.jp/ およびしゃろう様
・しゅわしゅわハニーレモン350ml
・SUMMER TRIANGLE
・Morning
Twitter: https://twitter.com/creator_marimo
note: https://note.com/creator_marimo